

Key takeaways
- GPTZero and ZeroGPT are different companies with confusingly similar names and very different track records.
- Independent studies show all major AI detectors score below 80% accuracy, with meaningful false-positive rates on human writing.
- A Stanford study found GPT detectors falsely flagged TOEFL essays from non-native English writers 61% of the time.
- GPTZero's free tier covers 10,000 words a month; paid plans start at $12.99/month with annual billing.
- If you're falsely flagged, gather version history and cite the Weber-Wulff and Liang studies before admitting anything.
On January 1, 2023, a Princeton senior posted a New Year's Day side project that promised to spot ChatGPT writing. Three years later, GPTZero is a funded company, a Chrome extension, and a name that gets confused with a totally separate product called ZeroGPT. The two aren't the same team, the same accuracy tier, or even the same business model.
This guide answers the three questions you actually care about: should you trust a GPTZero score, what do you do if it flags human writing, and is it the right tool for your use case? Every number here comes from published research, vendor pricing pages, or independent benchmarks. No vibes.
What GPTZero Is (and Who Actually Built It)
GPTZero started as a New Year's Day side project. On January 1, 2023, Princeton senior Edward Tian posted a tool that claimed to spot ChatGPT-written text. Within a week, around 30,000 people had tried it, and Streamlit (the host) had to spin up extra servers to keep the site up.
Edward Tian, Princeton, and the January 2023 launch
Tian was studying computer science and journalism. His pitch was simple: teachers needed a way to check whether the essay in front of them came from a person or a language model. He co-founded the company with Alex Cui shortly after launch.
From dorm-room project to $13.5M in funding
Money followed fast. GPTZero raised a $3.5M seed in May 2023, then a $10M Series A led by Footwork VC in June 2024, bringing total funding to $13.5M. User counts climbed from 1 million in mid-2023 to 4 million a year later, and the company now claims 8 million+ users on its product pages. An October 2023 partnership plugged it into the American Federation of Teachers, which represents 1.7 million educators. Sacra pegged 2025 ARR at roughly $24M, up 253% year over year (per Sacra's GPTZero profile).
If you're reading this in 2026, you probably fit one of three buckets: an educator weighing a GPTZero rollout, a student worried about a false flag, or a writer double-checking your own work before publishing. The rest of this guide is built around those three jobs.
What ZeroGPT Actually Is (and Why It Keeps Getting Mistaken for GPTZero)
ZeroGPT is the tool people land on when they mean to land on GPTZero, and that's most of the story. The name showed up after Edward Tian's launch went viral, the interface is cleaner, and the free tier lets you paste more text in one go. None of that makes it the same product.
The team nobody can name
GPTZero has founders you can look up. ZeroGPT does not. There's no published research, no founder LinkedIn pages linked from the site, no Series A announcement, no benchmark submissions. Reviewers who have tried to trace ownership have come back with shell-company registrations and not much else. For a tool that's adjudicating whether your writing is real, the anonymity is worth flagging.
What it actually does
Paste text, get a percentage, get sentence-level highlights in yellow or red. That part looks familiar because it copies the GPTZero output format closely. Underneath, ZeroGPT uses what it calls "DeepAnalyse Technology," a phrase the company has never broken down in any documentation, white paper, or model card. There's no public accuracy methodology.
The product page advertises 98%+ accuracy. Independent 2026 testing summarized by Stack Junkie put real-world accuracy near 73.8%, with false positives on human writing around 20.5%. That's roughly one in five genuine human submissions getting flagged. On any meaningful sample size, that number is the whole problem.
Pricing
The free tier is the main draw. You can scan longer chunks of text without an account, which is why casual users gravitate there for a quick check. Paid plans run roughly $9.99 to $18.99 a month depending on word limits and feature access. There's no documented API tier with published rate limits, no SOC 2 page, no FERPA posture, and no enterprise contact path beyond a generic form.
Who it makes sense for
If you want a free, no-signup gut check on a paragraph of your own writing before you hit publish on a blog post, ZeroGPT is fine for that. Nothing rides on it, the answer is directional, and you're not handing the score to anyone else.
If a score is going to influence a grade, a hiring decision, a refund, or a published byline, ZeroGPT is the wrong tool. There's no audit trail, no version-history export, no Writing Replay equivalent, no team you can escalate to, and a false-positive rate high enough that an ESL student or a fast typist gets flagged on roughly normal odds. Whatever you're trying to prove, you can't prove it with a ZeroGPT screenshot.
The bottom line on the name confusion
If someone tells you they "ran it through ZeroGPT," they probably did not mean to. Most of the time they meant GPTZero, saw the lookalike rank well on Google, and clicked the first result. Worth correcting in writing the moment it shows up in a misconduct email, an editor's note, or a hiring rejection. The two products are not interchangeable, and the difference is the entire reason you're reading any of this.
How GPTZero Works: Perplexity, Burstiness, and the New Authorship Tracking Layer
GPTZero leans on two signals you can picture. Perplexity asks how predictable each word is to a language model. If a sentence reads exactly the way a model would continue it, perplexity drops and the score tilts toward AI. Burstiness measures variation in sentence length and complexity. Humans bounce around. Models flatten out.
The 7-component detection stack
As of 2026, GPTZero runs seven layers on every submission: perplexity, burstiness, GPTZeroX (full-context sentence analysis), an Education module tuned for student writing, an internet text search for direct matches, GPTZero Shield (which flags humanized rewrites), and an end-to-end deep classifier trained on labeled samples.
Authorship Tracking and Writing Replay
In September 2024, GPTZero shipped Authorship Tracking through its Google Docs, Google Classroom, and Chrome extensions. You get Writing Replay video playback, copy/paste history, edit timelines, multi-user detection, and a "natural typing analysis" that watches keystroke rhythm. Teachers and students get it free during the school year, per the GPTZero pricing page.
How to read the output
Three things show up. A percentage score at the top. A bucket label the API returns as HUMAN_ONLY, MIXED, or AI_ONLY. And sentence-level highlighting in yellow or red, so you can see which lines triggered the call instead of trusting one summary number.
How Accurate Is GPTZero in 2026? What the Studies Actually Say
Short answer: better than most, still not good enough to stand alone as evidence.
The Weber-Wulff multi-detector benchmark
The most-cited independent study, Weber-Wulff et al. (2023) in the International Journal for Educational Integrity, tested 14 detectors on AI and human writing. None cleared 80% accuracy. Only five cracked 70%. GPTZero was in the pack, not miles ahead. Anchor to that before any vendor marketing.
GPTZero's claims vs independent tests
GPTZero advertises around 99% accuracy on its internal benchmarks. Independent tests tell a messier story: false positive rates on real human writing land between roughly 8.6% and 12.5%, depending on the dataset. The RAID benchmark and a 2026 Chicago Booth analysis are kinder, but those are controlled conditions. Classroom reality runs higher, especially on ESL writing and short answers.
The 2026 frontier-model problem
Here's the part most reviews skip. Nearly every public accuracy study tested output from GPT-3.5, GPT-4, Claude 3, or LLaMA-era models. Almost none cover Claude Opus 4.7, GPT-5.5, or Gemini 3.1 Pro. Perkins et al. (2024) found detector accuracy collapsed from about 39.5% to 22.1% after basic manual editing of AI text. Paraphrased and hybrid human-plus-AI writing degrades scores further.
The honest read for 2026: GPTZero is among the stronger tools you can use, and it's nowhere near reliable enough to be the only thing a grade, a job, or a publishing decision rests on.
GPTZero Pricing in 2026: Free Tier, Paid Plans, and What Each One Actually Includes
GPTZero runs a freemium model, and the gaps between tiers matter more than the sticker prices. Here's what you actually get at each level in 2026.
Free tier
You get 10,000 words per month, basic AI scanning, multilingual detection, and sentence-level highlighting. No credit card needed. Third-party reviewers note a 5,000-character cap per scan and a 3-scans-per-hour rate limit. Signup is required, and there's no anonymous mode, so your text and account stay linked.
Premium and Professional
Premium is $12.99/month on annual billing. That gets you 300,000 words/month, downloadable AI reports, an advanced scan, and the AI Vocabulary feature that flags suspect phrases. Professional jumps to $24.99/month annual and adds 10 million overage words, batch scanning of up to 250 files, page-by-page analysis, enterprise-grade security, LMS integration, and bundled API access. Annual billing shaves roughly 45% off the monthly rate. Steep enough that month-to-month only makes sense for a short trial.
Classroom, Enterprise, and API
Teams plans, a Premium Educator tier, and Enterprise API access run on custom volume pricing. Scanning across a district or publication? You'll talk to sales. The API being bundled into Professional is unusually generous, since most detection vendors gate API access behind a separate contract.
Free: 10K words/mo, basic scan, rate-limited
Premium ($12.99/mo annual): 300K words, reports, AI Vocabulary
Professional ($24.99/mo annual): batch, LMS, API included
Enterprise: custom
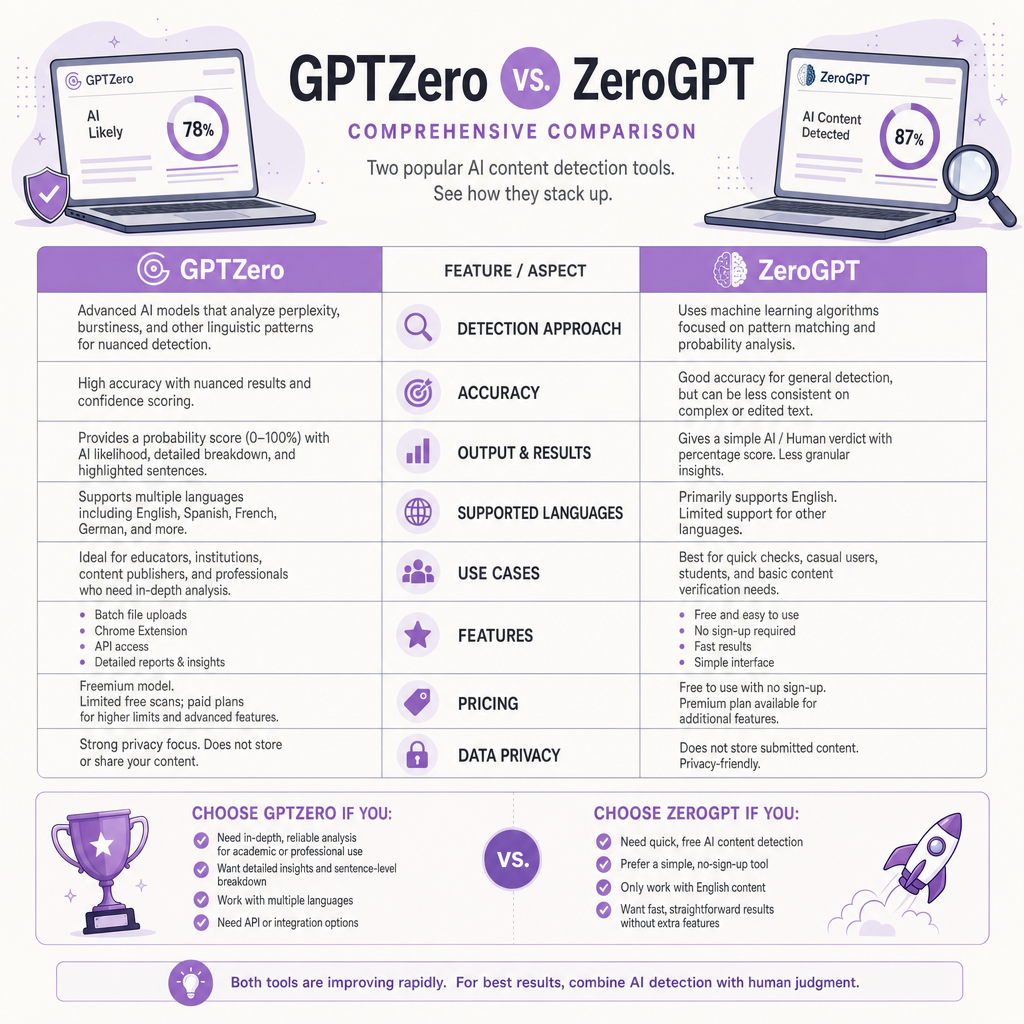
How GPTZero stacks up to ZeroGPT
The ESL False-Positive Problem and Why Universities Are Backing Away
The Stanford 61% finding
One study reframed the entire debate. Liang et al. (Stanford, 2023, published in Patterns) ran seven popular GPT detectors against 91 TOEFL essays written by non-native English speakers. The average false-positive rate hit 61.3%. Nearly 20% of those essays were unanimously misclassified by all seven detectors, and 97.8% got flagged by at least one. Then the researchers tried something clever: they asked ChatGPT to enrich the vocabulary of the same essays. The false-positive rate cratered to 11.77%. The bias isn't about AI authorship. It's about limited linguistic variability getting punished.
12+ universities that pulled AI detection
Vanderbilt killed its detector in August 2023. The math was blunt: a vendor-claimed 1% false-positive rate across 75,000 annual submissions still wrongly accuses about 750 students. Johns Hopkins, Northwestern, UCLA, UC San Diego, Yale, Penn State, Michigan State, Oregon State, and the University of Waterloo have stepped back since. UT Austin banned new detector purchases outright. Australian Catholic University accused roughly 6,000 students of misconduct in 2024 (per ABC News); about a quarter of referrals were dismissed, and cases resting solely on detector scores were dropped.
Why this matters legally
If a tool disproportionately flags ESL writers, you're past academic integrity. You're into FERPA documentation problems and Title VI national-origin discrimination exposure. That's a legal problem, not a software one.
GPTZero vs Originality.ai, Turnitin, Copyleaks, Winston AI, and ZeroGPT
The biggest source of confusion here is the name. The Princeton-built tool is one product. The lookalike with the minimalist black-and-white interface is a different company that launched later with a near-identical name. Different teams, different models, different track records.
The brand-confusion comparison
Independent 2026 testing summarized by Stack Junkie put the lookalike's overall accuracy near 73.8%, with a 20.5% false-positive rate on human writing. The Princeton tool reports 95.7% detection at a 1% false-positive rate on the RAID benchmark. The lookalike bundles a paraphraser, summarizer, and grammar checker, but publishes no model version history you can audit.
Where each tool actually wins
Originality.ai targets SEO teams and publishers, bundles plagiarism checks, and claims a sub-2.5% false-positive rate (the company publicly disputed the Stanford ESL bias study). Turnitin still anchors institutional workflows across 16,000+ schools, but acknowledges a ±15 percentage-point variance and intentionally lets roughly 15% of AI content through to keep false positives under 1%. Many universities are pulling back regardless. Copyleaks is the usual enterprise alternative. Winston AI courts publishers and agencies at higher price points.
How to pick
- Compare on: free tier, monthly price, claimed accuracy, ESL handling, multilingual support, API access, primary use case.
- Quick read: pick by workflow, not marketing copy. Educators, publishers, and SEO teams each land on a different best fit.
What to Do If GPTZero Falsely Flags Your Writing
A false flag isn't a verdict. It's an accusation, and you have more leverage than you think.
The first 48 hours: don't panic, don't confess
Don't admit to using AI you didn't use. Many universities explicitly forbid treating a detector score as sole proof of misconduct, so one percentage isn't a verdict. Request a meeting in writing. Ask which detector was used, the exact score, and what corroborating evidence exists beyond that number.
Evidence to start collecting today
- Google Docs or Word version history showing incremental edits across hours or days
- Browser history with research sources, timestamps, and tabs open while you wrote
- Handwritten notes, outlines, earlier saves, scratch files
- If you used GPTZero's Chrome extension or Writing Replay, export the PDF Writing Report showing keystrokes, paste events, and your edit timeline
- Screenshots showing AI tools you did not have open
How to escalate
Cite the research. Weber-Wulff et al. (2023) found AI detectors scored under 80% accuracy across 14 tools. Liang et al. (Stanford, 2023) documented a 61% false-positive rate on essays by non-native English writers. Name the schools that have officially turned detection off: Vanderbilt, Yale, Johns Hopkins, UCLA. Then pull up your school's academic-integrity appeals policy and follow it line by line.
If you're an ESL writer, say so in writing. The documented bias is admissible context, and any reasonable committee should weigh it.
Should You Use GPTZero? A Decision Framework by Use Case
Educators
Use it if you want sentence-level highlighting and the Writing Replay feature, which captures typing patterns as process evidence. The Chrome extension and Google Docs integration are the strongest in the category. The free tier is generous enough to spot-check assignments. Don't make a flag the sole basis for a misconduct charge. Pair any alert with a conversation, the document's version history, and an in-person follow-up. Check with your institution before uploading student work anywhere, even to tools advertising SOC 2 and FERPA compliance. That badge doesn't answer your district's data-flow policy for you.
Students and ESL writers
If English isn't your first language, a 2023 Stanford study by Liang et al. found detectors flagged non-native English writing as AI-generated at sharply higher rates than native samples. Keep version history on. Save Google Docs revision logs. Screenshot timestamps. That paper trail matters more than any score.
Hiring managers and publishers
For site-level scanning with bundled plagiarism checks, a publisher-focused detector fits better. For enterprise compliance, look at tools built for that workflow. Any score is one signal, not a verdict.
When to look elsewhere
Short text, paraphrased text, heavily edited text, or output from GPT-5.5, Claude Opus 4.7, or Gemini 3.1 Pro: no detector handles these reliably. A 2023 benchmark doesn't predict 2026 behavior. Treat every score as a hypothesis.
Frequently asked questions
Sources (7)
- 1.Liang et al. (2023), 'GPT detectors are biased against non-native English writers,' Patternssciencedirect.com
Primary research showing the 61.3% false-positive rate on TOEFL essays — the foundational citation for the ESL-bias section.
- 2.Weber-Wulff et al. (2023), 'Testing of detection tools for AI-generated text,' International Journal for Educational Integritylink.springer.com
Peer-reviewed study of 14 detectors including GPTZero — source for the 'all scored below 80% accuracy' headline number.
- 3.Vanderbilt University: Why We're Disabling Turnitin's AI Detector (Aug 2023)vanderbilt.edu
Primary institutional source for the 1% FPR × 75,000 submissions = 750 false accusations math and the broader university backlash.
- 4.The Markup: AI Detection Tools Falsely Accuse International Students of Cheatingthemarkup.org
Established journalism documenting real classroom cases at Johns Hopkins and the ESL bias problem in the wild.
- 5.Wikipedia: GPTZeroen.wikipedia.org
Neutral biographical and funding-history source: founder, launch date, seed and Series A rounds, AFT partnership, Authorship Tracking launch.
- 6.PR Newswire: GPTZero Releases Authorship Tools (Sept 18, 2024)prnewswire.com
Primary announcement of the September 2024 Authorship Tracking / Writing Replay launch with feature list.
- 7.Sacra: GPTZero revenue, funding & newssacra.com
Financial detail on the $24M ARR estimate (2025), the June 2024 Series A led by Footwork VC, and AFT partnership scale.



